Transplantation of Support Vector Machine Speech Recognition Algorithm on OMAP5912
1 SVM multi-class classification method SVM was originally designed to deal with two types of classification problems. How to effectively deal with multi-class classification problems is still a subject of continuous research. Multi-class classification is implemented by the "one-to-one" method in SVM. The following is a brief introduction.
S. Knerr et al. first introduced the "one-on-one" approach in 1990. J. In 1996, Friedman and U KreBel first used this method in support vector machines in 1999. It needs to construct k(k-1)/2 classifiers, each classifier is trained by certain two types of training samples. When determining the category of test samples, combined with the judgment opinions of all two types of classifiers on the test sample categories. The strategy of using the "voting method" and considering that the category with the highest number of votes (Max Wins) is the category to which the test sample belongs. The details are as follows: Consider the classification problem of K class, set the training set 
First, all (i, j) ∈ {(i, j)|i ≤ j, i, j = 1, ..., K} are operated: all sample points of y = i and y = j are extracted from the training set. Based on these sample points to form a training set Ti-j, each of the two types of classification SVM solves the problem 
The constraints are: 
Get k(k-1)/2 decision functions by solving the optimization problem of equation (3), if the function ![]() When it is judged that x belongs to the i class, the number of votes of the i class is increased by 1; otherwise, the number of votes of the j class is increased by 1. The category that ultimately determines the number of votes is the category to which the test sample x belongs.
When it is judged that x belongs to the i class, the number of votes of the i class is increased by 1; otherwise, the number of votes of the j class is increased by 1. The category that ultimately determines the number of votes is the category to which the test sample x belongs.
The "one-to-one" method is characterized by the need to construct k(k-1)/2 classifiers during training and the voting selection strategy for prediction. The advantage of this is that each classification problem is small in scale, the problem to be asked is relatively simple, the training speed is faster when the sample size is not large, and the sample rejection is improved due to the small overlap of the categories. The disadvantage is that the voting method may have the same class with the same votes, that is, there may be a case where one sample belongs to multiple classes at the same time. This can be solved using other methods. Here we focus on the implementation of the SVM algorithm on 0MAP.
2 Embedded System Development Environment The 0MAP5912 processor is a dual-core application processor consisting of TI's TMS320C55x DSP core (192 MHz) and a low-power, enhanced ARM926EJ-S microprocessor (192 MHz). .13μm CMOS process manufacturing. The TMS320C55x DSP provides real-time multimedia processing support for low-power applications; the ARM926EJ-S MPU meets the processing needs of both control and interface. The dual-core architecture of the 0MAP5912 is extremely computationally efficient and extremely low power, with an open, easy-to-develop software facility that supports a wide range of operating systems. After solving the design of the hardware platform and the establishment of the operating system, the embedded system development needs to consider how the application is compiled, how the host communicates with the development board, how the program is debugged, and how the program is downloaded to the development board.
2.1 Communication environment adopts minicom communication terminal program. Through minicom, it can set and monitor the working status of the serial port, receive and display the information received by the serial port, and transfer data and control commands between the host and the development board to realize the host computer. The purpose of debugging the development board.
Set the minicom parameter values ​​as follows: "Serial Device" is /dev/ttyrSO (using serial port 1); host serial port baud rate is 115 200; data bit is: 8 bits; stop bit is: 1 bit; parity bit is : None; data flow control is: None. Save the settings and restart Minicom after saving.
2.2 Program download environment During program development, it is often necessary to download the program to the development board for testing. The general development mode is adopted: the host and the development board are connected via Ethernet, and minicom is run on the host machine as the display of the development board. The terminal mounts the host hard disk through NFS (Network File System) to let the application run directly on the development board.
2.3 The cross-compilation environment is established. The host system is Ubuntu version 2.6.27. The cross-compilation tool arm-linux-gcc-3.4.1 is decompressed into the /usr/local/arm directory, and then in the terminal. Execute the command: #gedit/root/. Bashrc, modify /root/. Bashrc file, add export PATH=“$PATH:/sbin:/usr/local/arm/3.4.1/bin:/usr/local/bin:/usr/local†to the file, and finally execute the command in the terminal. #source. Bashrc. At this point, the cross-compilation environment is set up. Both resource files and library files are installed in the /usr/local/arm/3.4.1/arm-linux directory. The cross-compilation process is shown in Figure 1.
This article refers to the address: http://
2.4 Installing NFS "Network File System"
It is convenient to use NFS in the development phase, so that the root file system of the development board can be placed on the host machine and then mounted and run through NFS. The kernel can also be placed on the host computer and then retrieved by the bootloader via Ethernet using the TFTP (Trivial File Transfer Protocol) protocol. The development board has both an Ethernet port and a serial port, and the transmission speed of the Ethernet connection is much faster than that of the serial port connection. Therefore, the kernel and the root file system are downloaded using the Ethernet interface, and the serial port is used as a debug and console.
2.4.1 Installing NFS
Ubuntu defaults to no NFS service. First install the NFS server, #sudo apt-get install nfs-kernel-server, so that the host is equivalent to the NFS server. Similarly, the development board as an NFS client requires an NFS client program: #sudo apt-get install nfs-commmon.
2.4.2 Configuring the portmap service nfs-common and nfs-kernel-setver both depend on the portmap, so you need to configure the portmap. #sudo dpkg-reconfigure portmap, selectS for Shouldportmap be bound to the loopback address?.
In /etc/hosts. Deny and /etc/hosts. Allow access to the portmap in the two files: first in /etc/hosts. In deny, all users are denied access to portmap, then in /etc/hosts. Allow allows specific users to access the portmap. Execute #sudo/etc/init after the file is modified. d/pottmap restart, restart the portmap daemon to make the changed content take effect.
2.4.3 Configuring /etc/exports
The NFS mount directory and permissions are defined by the /etc/expotts file. Add a statement at the end of the file:
/data/rootfs2.6 192.168.0. *(rw,sync,no_root_squash)
Make 192.168. O. * The NFS client in the network segment can share the contents of the NFS server /data/rootfs2.6 directory, not only the write permission, but also the root after entering the /data/rootfs-2.6 directory. Update the configuration and restart the NFS service.
#sudo exportfs-r
#sudo/etc/init. d/nfs-kernel-server restait
2.4.4 Copying the root file system Copy the root file system to the /data/rootfs2.6 directory. At this point, you can start minicom as a virtual terminal, which can be used to operate the development board.
2.5 Modify the development board startup items
The bootargs parameter sets the JFFS2 root file system mounted on the NOR Flash when the Linux system starts. To mount the network file system on the host, the bootargs parameter should be set to setenv bootargs=console=ttyS0,115200n8 noinitrd rw ip=192.168.0.158 root=/dev/nfs nfsroot=192.168.0.204: /data/rootfs2.6. Nolock mem=62M
#sayenvReset u-boot after saving the settings, then go to the development board and debug the application.
3 Experiment and result analysis Based on VC++6.0 programming, a multi-class classification SVMs algorithm is implemented. The PC environment is Ubuntu version 2.6.27, the development board is ARM926ej-s of Omap5912, and the environment is Lin-ux version. 2.6.18; Boot Loader uses u-boot version 1.1.6; cross-compilation toolchain arm-linux-gcc version 3.4.1.
Sixteen people were used to pronounce 50 words of isolated words, and the speech data obtained under different signal-to-noise ratios (15, 20, 25, 30 dB and no noise) were used as samples, and the characteristic parameters obtained by the MFCC feature extraction algorithm were used as Identify the input to the network. The speech signal sampling rate is 11.025 kHz, the frame length is N = 256 points, and the frame shift is M = 128 points. The vocabulary is 10, 20, 30, 40 and 50 words respectively. The training sample was obtained by 9 people each time at 15, 20, 25, 30 dB and 3 times without noise. The test sample was obtained by another 7 people pronounced 3 times for each word at the corresponding SNR. The recognition algorithm adopts the SVM algorithm of RBF kernel function, adopts cross-validation and grid search method to select the kernel parameters and establish a model to classify and identify the test samples. The kernel function parameter is optimally (c, y) = (32.0, O.000 122 070 312 5). The experimental results are shown in Table 1, and the recognition rates are all above 95%. Table 1 also lists the recognition results using the HMM identification network under the same conditions.
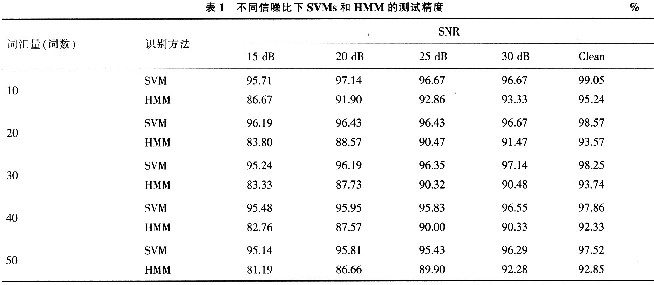
The HMM model is a typical speech recognition model, which is one of the few methods with the best speech recognition. SVM and HMM model are compared under the same characteristic parameters. The experimental results show that: 1) SVM has higher recognition rate than HMM model; 2) Comparing the same SNR and vocabulary test accuracy, HMM can be found The test accuracy of the model has dropped significantly, while the SVM test results have decreased less, indicating that the SVM is more popular than the HMM model.
4 Conclusion This paper proposes an implementation method of 0MAP5912 non-specific embedded speech recognition system based on SVM. In the built development environment, the SVM algorithm towel "one-to-one" method is used for speech recognition, and good results are obtained. It can be concluded from experiments that the MFCC feature parameters are used for small and medium vocabulary, and the one-to-one SVM can be used as the back-end recognition method to obtain better recognition results, which has obvious advantages over the traditional HMM model. At the same time, the SVM algorithm is integrated into the 0MAP5912 embedded system as an application, and the storage capacity is small, which can meet the practical requirements.