Stripping the mysterious coat of machine reading comprehension
In recent times, a fascinating development has emerged in the field of machine reading comprehension (MRC), sparking widespread interest and discussion. Let’s dive into this intriguing topic with Xiaobian, our network communication guide.
On February 21st, Baidu’s V-Net model, developed by its natural language processing team, achieved a significant milestone by topping Microsoft’s MS MARCO benchmark with a Rouge-L score of 46.15. This achievement highlights the rapid progress being made in AI-driven reading comprehension tasks.
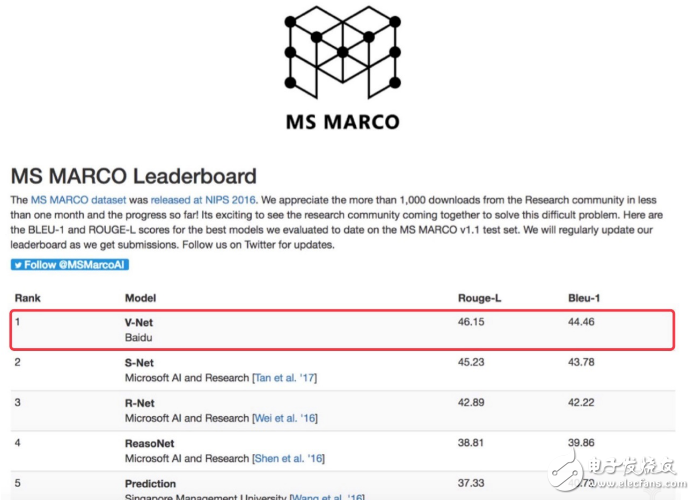
The question is no longer whether machines can read — it's about how well they understand. Beyond the SQuAD competition at Stanford University, teams such as Alibaba, Harbin Institute of Technology, and United Laboratories have already surpassed human average performance. This signals that two of the most prestigious MRC benchmarks — MS MARCO and SQuAD — have been broken by Chinese research groups.
Yet, amid the excitement of this “AI arms race,†there are deeper concerns. Behind the scenes, debates and controversies continue to arise. Why did Microsoft launch a new dataset and competition after SQuAD? Why does the academic community remain divided on the direction of MRC research?
These questions ultimately point to a fundamental one: What is the true purpose of AI in reading comprehension?
Let’s explore the evolving landscape of MRC and what the future might hold for this rapidly advancing technology.
### Two Big Datasets Confrontation: Problems and Controversies in Machine Reading Comprehension
At its core, machine reading comprehension is similar to the reading comprehension exercises we encountered during school. A passage is provided, along with questions, and the system must generate the correct answer. The difference lies in the fact that instead of students, it’s AI models that take the test.
This field, much like the ImageNet competition in computer vision, revolves around official datasets and competitive races. Major tech companies and top AI research labs from around the world participate in these challenges.
Baidu’s involvement in the MRC space began with Microsoft’s MS MARCO dataset, launched in late 2016. What makes this dataset unique is that it uses real-world user queries and answers collected from Bing search logs. These are then manually curated into training data, allowing AI models to learn from scenarios that closely resemble real applications.
Many believe that Microsoft’s dataset is more challenging than SQuAD, which was created by Stanford in 2016. Unlike MS MARCO, SQuAD relies on Wikipedia articles and human-generated questions and answers. While this approach is effective for testing AI capabilities, it has faced criticism for being too simplistic.
For instance, Yoav Goldberg, a leading researcher in NLP, has pointed out several issues with SQuAD:
1. **Questions are too straightforward** – Most answers are directly extracted from the text, making them easy to identify.
2. **Lack of diversity** – With only 536 articles, the dataset lacks the richness needed for real-world applications.
3. **Limited generalization** – The structure of the questions is often simple, reducing the need for complex reasoning.
In contrast, MS MARCO problems are designed to mimic real-life language use, requiring AI to analyze context and reason through complex queries.
While some prefer SQuAD for its simplicity, others argue that MS MARCO better reflects human-like interaction. However, both sides agree on one thing: the practical value of machine reading comprehension is becoming increasingly important in the industry.
### Attack Dataset: AI Reading Also Values "Quality Education"
Despite its controversies, the MS MARCO dataset has inspired a growing number of similar datasets focused on real-world data. This trend suggests a shift from "test-oriented" AI training to a more holistic, quality-based approach.
SQuAD, while useful for evaluating AI performance, has been criticized for being too narrow in scope. Many researchers argue that it’s overemphasized in competitions, leading to a focus on metrics rather than real-world applicability.
Models trained on real-world data from the internet and product interactions are seen as more relevant and practical. In fact, machine reading comprehension is already embedded in many of the services we use daily.
For example, when users search for information online, traditional methods rely on keyword matching or manual assistance — both of which lack efficiency and accuracy. AI-powered agents, however, need to go beyond simple extraction and provide meaningful insights. That means understanding context, analyzing multiple sources, and offering comprehensive solutions.
Another area where this is critical is in content recommendation systems. Recent controversies around platforms like Toutiao highlight the limitations of purely keyword-based algorithms. Without strong MRC capabilities, these systems fail to grasp the depth and nuance of user needs.
Similarly, voice assistants and chatbots require robust MRC to interpret complex queries and deliver accurate, personalized responses. Training AI on real-world data is essential to achieving this level of performance.
### Chinese, General, Application: The Future of MRC
Looking ahead, several trends are emerging in the field of machine reading comprehension. First, while most datasets and competitions have historically focused on English, this is beginning to change.
For instance, Baidu recently released DuReader, a large-scale Chinese dataset similar to MS MARCO. With 200,000 real questions, 1 million documents, and 420,000 manually written answers, it marks a major step toward developing MRC technologies tailored for the Chinese market.
Additionally, efforts are underway to make MRC more generalizable and compatible with other NLP systems. The goal is not just for machines to “read,†but also to understand, summarize, reason, and even create.
As MRC becomes more integrated into search engines, customer service, and content platforms, its impact will be felt across industries. In the near future, we may experience subtle yet significant improvements in how information is presented and consumed.
Ultimately, the future of machine reading comprehension is not just about machines reading questions — it’s about machines reading *you*.
Computer Case, Desktop Computer Case, Console Case,Gaming Computer Case,Boluo Xurong Electronics Co., Ltd.
Boluo Xurong Electronics Co., Ltd. , https://www.greenleaf-pc.com